참고 도서: 2022 유선배 SQL개발자 과외노트
참고 자료: Wikipedia, oracle.com, oracletutorial.com
** SQLD 자격 시험을 준비하는 분들께 도움이 되고자 정리한 내용을 올리고 있습니다.
** 암기가 필요한 부분은 계속 보면서 외워주세요.
** 실습 환경 구성이 어려운 분들은 아래 링크를 이용하세요.
Oracle Live SQL 👈 클릭
** 오류가 있다면 댓글 주세요!
3.1 관계형 데이터베이스 개요
3.1.1 관계형 데이터베이스란?
RDB라고 불리는 관계형 데이터베이스는 관계형 데이터 모델에 기초를 두고 있다.
모든 데이터를 2차원 테이블 형태로 표현한 뒤 각 테이블 간의 관계를 정의하는 것으로 설계가 시작된다.
RDBMS는 이러한 RDB를 관리﹒감독하기 위한 시스템이다.
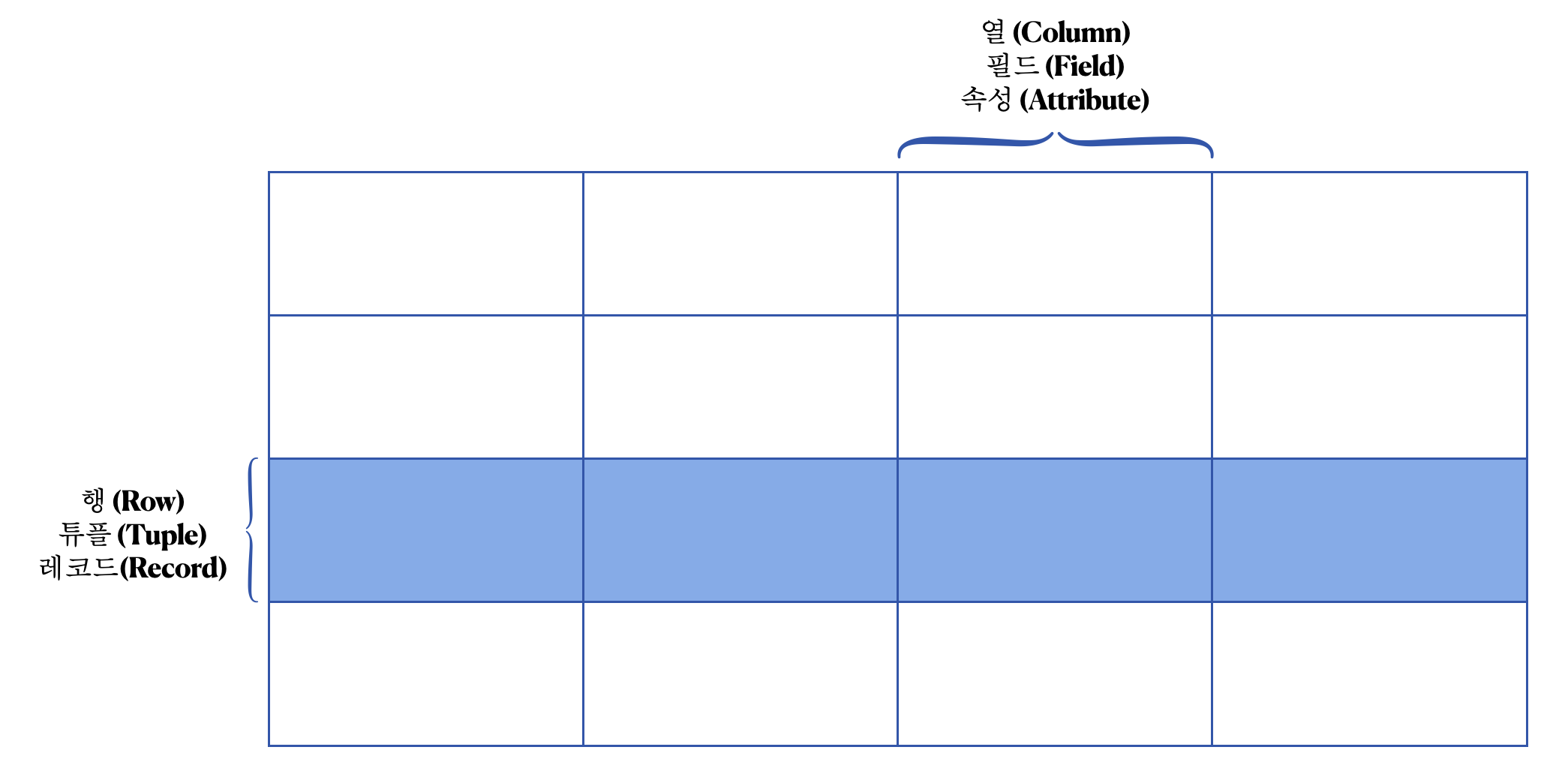
3.1.2 TABLE
3.1.3 SQL(Structured Query Language)
관계형 데이터베이스에서 데이터를 다루기 위해 사용하는 언어가 SQL이다.
3.2 SELECT 문
3.2.1 SELECT 문이란?
-
저장된 데이터를 🔍조회하고자 할 때 사용하는 명령어이다.
SELECT user_no, user_nm … FROM user WHERE user_no = ‘emp0000001’; -
컬럼을 따로 명시하지 않고 *를 사용하여 전체 컬럼을 조회할 수 있다.
SELECT ***** FROM 테이블; -
테이블명 또는 컬럼명에 별로의 별칭(Alias)을 붙여줄 수도 있다.
SELECT **u.**user_nm **AS name** FROM user **u**;
3.2.2 산술 연산자
| 연산자 | 의미 | 우선순위 |
|---|---|---|
| () | 괄호로 우선순위를 조정 | 1 |
| * | 곱하기 | 2 |
| / | 나누기 | 2 |
| + | 더하기 | 3 |
| - | 빼기 | 3 |
SELECT 10 + 5 AS add, 10 - 5 AS sub, 10 * 2 AS mul, 10 / 2 AS div, 48 / 2 * (9 + 3) AS ret FROM dual;
3.2.3 합성 연산자
-
SELECT ‘D’ || ‘E’ || ‘V’ AS ret FROM dual;
ret = DEV -
SELECT col1 || ‘ ‘ || ‘개발자’ || col2 AS ret FROM sample;
col1 = 나는
col2 = 입니다.
ret = 나는 개발자입니다.
3.3 함수
3.3.1 문자 함수
-
SELECT CHR(65) AS ret FROM dual;: 아스키 코드를 인수로 입력했을 때 매핑되는 문자를 리턴한다.
ret = A
⁉️ MSSQL인 경우 CHAR(ASCII 코드) -
SELECT LOWER('HELLO') AS ret FROM dual;: 문자열을 🔡소문자로 변경한다.
ret = hello -
SELECT UPPER('hello') AS ret FROM dual;: 문자열을 🔠대문자로 변경한다.
ret = HELLO -
SELECT LTRIM(' Theodore') AS ret FROM dual;: 왼쪽 공백을 제거한다.
ret = Theodore
⁉️ Oracle인 경우 LTRIM(문자열 [,특정문자]) 가능 [] 옵션 -
SELECT RTRIM('Samantha ') AS ret FROM dual;: 오른쪽 공백을 제거한다.
ret = `Samantha
⁉️ Oracle인 경우 RTRIM(문자열 [,특정문자]) 가능 [] 옵션 -
SELECT TRIM(' Amy ') AS ret FROM dual;: 문자열 양쪽의 공백을 제거한다.
ret = Amy
⁉️ Oracle인 경우 RTRIM([위치] [특정 문자] [FROM] 문자열) 가능-
TRIM(LEADING ‘T’ FROM ‘Theodore’) → heodore
-
TRIM(TRAILING ‘e’ FROM ‘Theodore’) → Theodor
-
-
SELECT SUBSTR('Hello, world!', 3, 3) AS ret FROM dual;: 특정 부분의 문자열을 잘라서 리턴한다.
ret = llo
⁉️ MSSQL의 경우 SUBSTRING(문자열) -
SELECT LENGTH('Amy') AS ret FROM dual;: 문자열을 길이를 리턴한다.
ret = 3
⁉️ MSSQL의 경우 LEN(문자열) -
SELECT REPLACE(UPPER('Love and work, work and love, that''s all there is.'), 'WORK', 'MONEY') AS ret FROM dual;: 문자열을 변경하여 리턴한다.
ret = LOVE AND MONEY, MONEY AND LOVE, THAT’S ALL THERE IS.
3.3.2 숫자 함수
-
SELECT ABS(-1) AS ret FROM dual;: 절대값을 리턴한다.
ret = 1 -
SELECT SIGN(-7) AS ret FROM dual;: 수의 부호를 리턴한다. (양수이면 1, 음수이면 -1)
ret = -1 -
SELECT ROUND(186.792, 1) AS ret FROM dual;: 지정된 소수점 자릿수까지 반올림하여 리턴한다.
ret = 186.8
SELECT ROUND(186.792, -2) AS ret FROM dual;
ret = 200 -
SELECT TRUNC=(186.792, 1) AS ret FROM dual;: 지정된 수소점 자릿수까지 버림하여 리턴한다.
ret = 186.7 -
SELECT CELL(186.792) AS ret FROM dual;: 소수점 이하의 수를 올림한 정수를 리턴한다.
ret = 187 -
SELECT FLOOR(186.792) AS ret FROM dual;: 소수점 이하의 수를 버림한 정수를 리턴한다.
ret = 186 -
SELECT MOD(-15, -4) AS ret FROM dual;: 수1을 수2로 나눈 나머지를 리턴한다.
ret = -3
SELECT MOD(15, -4) AS ret FROM dual;
ret = 3
SELECT MOD(-15, 0) AS ret FROM dual;
ret = -15
3.3.3 날짜 함수
-
SELECT SYSDATE AS ret FROM dual;: 현재의 연, 월, 일, 시, 분, 초를 리턴한다.
ret = 2022-12-22 22:28:01
⁉️ MSSQL인 경우 GETDATE()
⁉️ MYSQL인 경우 SYSDATE() -
SELECT EXTRACT({YEAR|MONTH|DAY} FROM SYSDATE) AS ret FROM dual;: 날짜 데이터에서 특정 단위만을 리턴한다. * {} 선택
ret = 2022
⁉️ MSSQL인 경우 DATEPART(특정 단위, 날짜 데이터) -
SELECT ADD_MONTHS(TO_DATE('2022-12-31', 'YYYY-MM-DD'), -1) AS ret FROM dual;: 날짜 데이터에서 특정 개월 수를 더해 리턴한다.
ret = 2022-11-30 00:00:00
⁉️ MSSQL인 경우 GETDATE()
3.3.4 변환 함수
-
명시적 형변환: 변환 함수를 사용하여 데이터 유형을 변환한다.
-
TO_NUMBER(’1234’)→ 1234 : 문자열을 숫자형으로 변환한다. -
TO_CHAR(1234)→ ‘1234’ : 수나 날짜형을 데이터를 문자형으로 변환한다.
TO_CHAR(SYSDATE, 'YYYYMMDD HH24MISS')→ ‘20221220 222801’ -
TO_DATE(20221220, 'YYYYMMDD')→ 2022-12-20 : 포맷 형식의 문자형 데이터를 날짜형 데이터로 변환한다.포맷 표현 의미 포맷 표현 의미 YYYY 년 HH 시(12) MM 월 HH24 시(24) DD 일 MI 분 SS 초
-
-
암시적 형변환: 데이터베이스가 내부적으로 데이터 유형을 변환한다.
3.3.5 NULL 관련 함수 🫥
-
NVL(arg1, arg2): 인수1(arg1)의 값이 NULL일 경우 인수2(arg2)를 반환하고 NULL이 아닐 경우 인수1을 리턴한다.
⁉️ MSSQL인 경우 ISNULL(arg1, arg2) -
NULLIF(arg1, arg2): 인수1(arg1)과 인수2(arg2)가 같으면 NULL을 반환하고 같지 않으면 인수1을 리턴한다. -
COALESCE(arg1, arg2, arg2…): NULL이 아닌 최초의 인수를 리턴한다. e.g.COALESCE(phone, email, fax)
3.3.6 CASE
CASE WHEN subway_line = '1' THEN 'blue'
WHEN subway_line = '2' THEN 'green'
WHEN subway_line = '3' THEN 'orange'
[ELSE 'gray']
END
CASE subway_line
WHEN '1' THEN 'blue'
WHEN '2' THEN 'green'
WHEN '3' THEN 'orange'
[ELSE 'gray']
END
DECODE (subway_line,
'1', 'blue',
'2', 'green',
'3', 'orange'
[,'gray']
)
3.4 WHERE 절
3.4.1 WHERE 절이란?
- INSERT를 제외한 DML문을 수행할 때 원하는 데이터만 골라 수행할 수 있도록 한다.
SELECT col1, col2 … FROM table WHERE …
3.4.2 비교 연산자, 부정 비교 연산자
| 연산자 | 의미 | 예시 (col1 = 20) |
|---|---|---|
| = | 같음 | WHERE col1 = 10 (false) |
| < | 적음 | WHERE col1 < 10 (false) |
| <= | 적거나 같음 | WHERE col1 <= 10 (false) |
| > | 큼 | WHERE col1 > 10 (true) |
| >= | 크거나 같음 | WHERE col1 >= 10 (true) |
| != | 같지 않음 | WHERE col1 != 10 (true) |
| ^= | 같지 않음 | WHERE col1 ^= 10 (true) |
| <> | 같지 않음 | WHERE col1 <> 10 (true) |
| NOT col1 = | 같지 않음 | WHERE NOT col1 = 10 (true) |
| NOT col1 > | 크지 않음 | WHERE NOT col1 > 10 (false) |
3.4.3 SQL 연산자, 부정 SQL 연산자
| 연산자 | 의미 | 예시 |
|---|---|---|
| BETWEEN a AND b | a와 b의 사이 (a, b 포함) | WHERE col1 BETWEEN 1 AND 10 |
| LIKE ‘String’ | 비교 문자열을 포함 | WHERE col1 LIKE ‘Theodore’ WHERE col1 LIKE ‘%dore’ WHERE col1 LIKE ‘%eod%’ |
| IN (List) | List 중 하나와 일치 | WHERE col1 IN (1, 2, 3, 5, 7, 9) |
| IS NULL | NULL 값 | WHERE col1 IS NULL |
| NOT BETWEEN a AND b | a와 b의 사이가 아님(a, b 미포함) | WHERE col1 NOT BETWEEN 1 AND 10 |
| NOT IN (List) | List 중 일치하는 것이 없음 | WHERE col1 IN (1, 2, 3, 5, 7, 9) |
| IS NOT NULL | NULL 값이 아님 | WHERE col1 IS NOT NULL |
3.4.4 논리 연산자
| 연산자 | 의미 | 예시 | 우선순위 |
|---|---|---|---|
| AND | 모든 조건이 TRUE = TRUE | WHERE 1 < col AND col < 10 | 2 |
| OR | 하나의 조건이 TRUE = TRUE | WHERE col > 10 OR col < 1 | 3 |
| NOT | TRUE면 FALSE, FALSE면 TRUE | WHERE NOT col = 1 | 1 |
3.5 GROUP BY, HAVING 절
3.5.1 GROUP BY 절이란?
데이터를 그룹별로 🎀묶을 수 있도록 해주는 절이다.
3.5.2 집계 함수
-
COUNT(*): 전체 Row를 Count하여 리턴한다. -
COUNT(col1): NULL값을 제외한 모든 Row를 Count하여 리턴한다. -
COUNT(DISTINCT col1): 👬중복 제거 및 NULL값을 제외한 모든 Row를 Count하여 리턴한다. -
SUM(col1): 컬럼의 합계를 리턴한다. -
AVG(col1): 컴럼의 평균값을 리턴한다. -
MIN(col1): 컬럼의 최솟값을 리턴한다. -
MAX(col1): 컬럼의 최대값을 리턴한다.
3.5.3 HAVING 절이란?
GROUP BY 절을 이용해 데이터를 그룹핑한 후 특정 그룹을 골라낼 때 사용한다.
HAVING 절은 논리적으로 SELECT 절 전에 수행된다.
SELECT 절에 명시되지 않은 집계 함수로도 조건을 부여할 수 있다.
WHERE 절을 사용해도 되는 조건까지 HAVING 절로 처리하면 성능상 불리할 수 있다.
SELECT 문의 논리적 수행 순서
SELECT— 5FROM— 1WHERE— 2GROUP BY— 3HAVING— 4ORDER BY— 6
3.5.4 ORDER BY
-
ORDER BY 절을 사용하여 SELECT한 데이터를 정렬할 수 있다.
-
ORDER BY 절을 사용하지 않을 경우 데이터는 임의의 순서로 출력된다.
-
ORDER BY 절 이후로 옵션이 붙을 수 있으며 다음과 같다.
-
ASC(default): 오름차순
-
DESC: 내림차순
-
⁉️ Oracle의 경우 NULL 값을 최대값으로 인식한다. 오름차순으로 정렬할 때 NULL 값이 맨 뒤에 위치하게 된다. 만약 값을 위치를 변경하고 싶다면 ORDER BY 절에 NULLS FIRST, NULLS LAST 옵션을 통해 정렬 순서를 변경할 수 있다.
3.6 JOIN
3.6.1 JOIN이란?
- 각기 다른 테이블을 함께 보여줄 때 사용한다. 실무에서 많이 사용하며 👩💻신입 개발자의 기술 면접시 단골 질문이다.
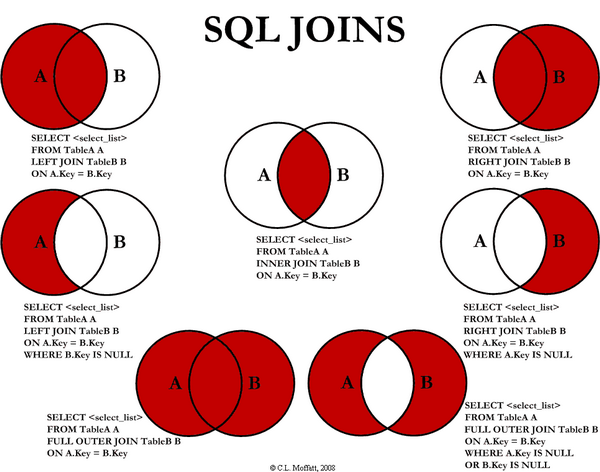
3.6.2 EQUI JOIN
- Equal(=) 조건으로 JOIN하는 것으로 자주 쓰인다.
-- scott schema
SELECT A.EMPNO
,A.ENAME
,A.JOB
,A.DEPTNO
,B.DNAME
,B.LOC
FROM EMP A
,DEPT B
WHERE A.DEPTNO = B.DEPTNO;
3.6.3 Non EQUI JOIN
- Equal(=) 조건이 아닌 다른 조건(BETWEEN, >, ≥, <, ≤)으로 JOIN하는 것으로 자주 쓰인다.
-- scott schema
SELECT EMPNO
,A.ENAME
,A.JOB
,A.DEPTNO
,B.DNAME
,B.LOC
FROM EMP A, DEPT B
WHERE B.LOC IN ('Seoul', 'Tokyo');
3.6.4 3개 이상 테이블 JOIN
-- scott schema
SELECT A.EMPNO
,A.ENAME
,A.SAL
,C.GRADE
,A.DEPTNO
,B.DNAME
FROM EMP A
LEFT OUTER JOIN DEPT B
ON A.DEPTNO = B.DEPTNO
INNER JOIN SALGRADE C
ON A.SAL BETWEEN LOSAL AND HISAL
ORDER BY A.SAL DESC;
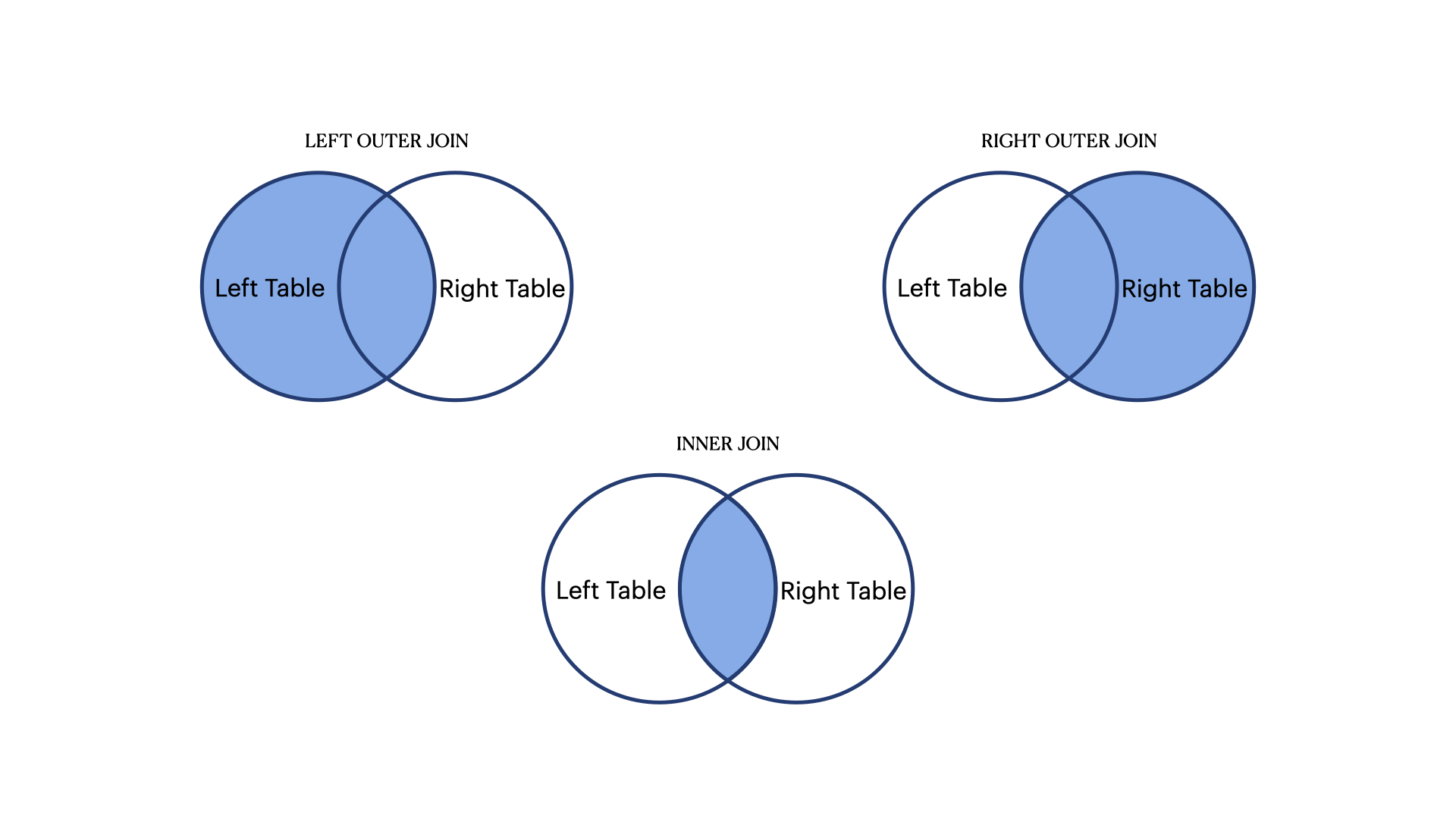
3.6.5 OUTER JOIN
- EQUI, Non EQUI JOIN과 다르게 조건에 일치하지 않는 Rows도 조회된다.
Oracle에서는 모든 행이 출력되는 테이블의 반대편 테이블에 (+) 기호를 붙여 작성한다.
-- scott schema
SELECT A.EMPNO
,A.ENAME
,A.JOB
,A.DEPTNO
,B.DNAME
,B.LOC
FROM EMP A
,DEPT B
WHERE A.DEPTNO = B.DEPTNO(+);
3.7 ANSI JOIN
3.7.1 ANSI JOIN이란?
-
데이터베이스를 관리하는 대부분의 Management System들은 SQL을 사용한다. 큰 틀에서 본다면 보편적이지만 DBMS 자체의 특수성으로 SQL의 사용법이 조금씩 상의하다. 문법의 차이로 호환성 이슈가 발생하면 SQL을 사용하는 사람들 입장에서 불편하다. 이를 극복하기 위해 표준이 되는 ANSI SQL이 지정되었다.
-
SQL INNER JOIN (sometimes called simple join)
-
SQL LEFT OUTER JOIN (sometimes called LEFT JOIN)
-
SQL RIGHT OUTER JOIN (sometimes called RIGHT JOIN)
-
SQL FULL OUTER JOIN (sometimes called FULL JOIN)
-
3.7.2 INNER JOIN
-
조건에 충족하는 데이터만 조회한다.
-- scott schema SELECT A.EMPNO ,A.ENAME ,A.JOB ,A.DEPTNO ,B.DNAME ,B.LOC FROM EMP A INNER JOIN DEPT B ON A.DEPTNO = B.DEPTNO;
3.7.3 OUTER JOIN
-
JOIN 조건에 충족하지 않는 데이터도 조회될 수 있는 조건이다.
-
LEFT OUTER JOIN
- 왼쪽에 표기된 테이블의 데이터가 모두 조회된다. JOIN되는 테이블에 조건을 충족하는 데이터가 없다면 NULL로 출력된다.
ID (A) NAME (A) ID (B) NAME (B) 1 A 1 B 2 C 2 C 3 A 3 C 4 B 4 B 5 F SELECT * FROM TABLE_A A LEFT OUTER JOIN TABLE_B B ON A.ID = B.ID AND A.NAME = B.NAME; -- Output -- 1|A -- 2|C|2|C -- 3|A -- 4|B|4|B -- 5|F -
RIGHT OUTER JOIN
- 오른쪽에 표기된 테이블의 데이터가 모두 조회된다. JOIN되는 테이블에 조건을 충족하는 데이터가 없다면 NULL로 출력된다.
SELECT * FROM TABLE_A A RIGHT OUTER JOIN TABLE_B B ON A.ID = B.ID AND A.NAME = B.NAME; -
FULL OUTER JOIN
- 왼쪽, 오른쪽 테이블의 모든 데이터가 조회된다. (중복값은 미출력)
SELECT * FROM TABLE_A A FULL OUTER JOIN TABLE_B B ON A.ID = B.ID AND A.NAME = B.NAME; -- Output -- 1|A -- 1|B -- 2|C -- 3|A -- 3|C -- 4|B -- 5|F
3.7.4 NATURAL JOIN
-
A 테이블과 B 테이블에서 같은 이름을 가진 컬럼들이 모두 동일한 데이터를 가지고 있을 경우 출력된다.
⁉️ USING 조건절을 이용하여 원하는 컬럼만 JOIN 할 수 있다.
⁉️ USING 절로 정의된 컬럼 앞에는 ALIAS 또는 테이블명을 붙일 수 없다.SELECT * FROM TABLE_A A NATURAL JOIN TABLE_B B; -- Output -- 2|C -- 4|B -- scott schema SELECT A.EMPNO, A.ENAME, DEPT, B.DNAME FROM EMP A NATURAL JOIN DEPT B
3.7.5 CROSS JOIN
-
A 테이블과 B 테이블에서 조합할 수 있는 모든 경우가 출력된다. 다른 말로 곱집합(Cartesian Product)이라고도 한다.
SELECT * FROM TABLE_A A CROSS JOIN TABLE_B B; -- Output -- 1|A|1|B -- 1|A|2|C -- 1|A|3|C -- 1|A|4|B -- 2|C|1|B -- 2|C|2|C -- 2|C|3|C -- 2|C|4|B ... -- 5|F|4|B